-
240117_포스코 아카데미 빅데이터 정형화(3)카테고리 없음 2024. 1. 17. 11:28
plt.hist(df["CO2배출량"], bins=100) plt.show()plt.figure(figsize=(10,10)) for i, column in enumerate(df.select_dtypes(include="number").columns): plt.subplot(2,2,i+1) plt.hist(df[column]) plt.title(column)plt.figure(figsize=(10,10)) for i, column in enumerate(df.select_dtypes(include="number").columns): plt.subplot(2,2,i+1) plt.boxplot(df[column]) plt.title(column)2. 범주형 변수 분포 : 막대 그래프
df.select_dtypes(include="category")plt.figure(figsize=(10,15)) plt.subplots_adjust(hspace=0.6) for i, column in enumerate(df.select_dtypes(include="category").columns): plt.subplot(3,2,i+1) plt.bar(df[column].value_counts().index, df[column].value_counts()) plt.title(column) plt.xticks(rotation=90)3. 수치형 - 수치형 관계 : 산점도
plt.scatter(df["배기량"], df["CO2배출량"]) plt.xlabel("배기량") plt.ylabel("CO2배출량")plt.figure(figsize=(10,15)) plt.subplots_adjust(hspace=0.2) for i, column in enumerate(df.select_dtypes(include="number").drop("CO2배출량",axis=1).columns): plt.subplot(2,2,i+1) plt.scatter(df[column], df["CO2배출량"]) plt.xlabel(column) plt.ylabel("CO2배출량")4. 범주형 - 수치형 관계 : 박스플롯
df.groupby("변속기")["CO2배출량"].mean()변속기 AT 270.189804 CVT 237.713164 MT 226.766827 Name: CO2배출량, dtype: float64plt.boxplot([df[df["변속기"] == "AT"]["CO2배출량"],df[df["변속기"] == "CVT"]["CO2배출량"],df[df["변속기"] == "MT"]["CO2배출량"]]) plt.xlabel("변속기") plt.ylabel("Co2배출량") plt.xticks(ticks=[1,2,3],labels=["AT","CVT","MT"]) plt.show()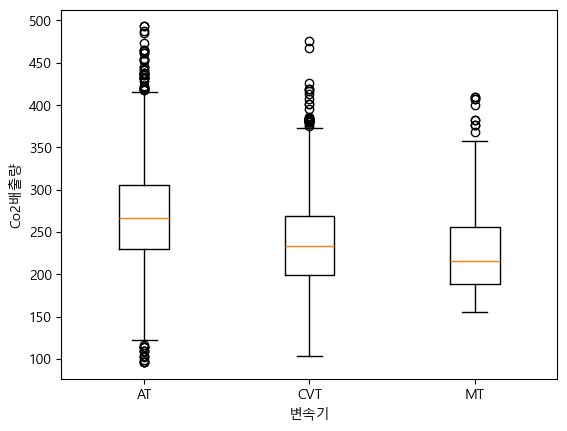
sns.boxplot(x=df["변속기"],y=df["CO2배출량"],hue=df["연료"],palette="Set1")
plt.figure(figsize=(10,15)) plt.subplots_adjust(hspace=1) for i, column in enumerate (df.select_dtypes(include="category").columns): plt.subplot(3,2,i+1) sns.boxplot(x=df[column],y=df["CO2배출량"],palette="Set1") plt.xticks(rotation=90)plt.hist(df["CO2배출량"], bins=100) plt.show()
실습 8 : 상관분석
-
- 수치형 변수간의 상관계수 확인하기
- 결과변수 CO2배출량과 입력변수간 상관계수 확인하고, 크기순으로 정열하기
- 결과변수 CO2배출량과 입력변수간 상관계수 크기를 그래프로 그리기
1. 수치형 변수간의 상관계수 확인하기
df.select_dtypes(include="number").corr()
2. 결과변수 CO2배출량과 입력변수간 상관계수 확인하고, 크기순으로 정열하기
df.select_dtypes(include="number").corr()["CO2배출량"].drop("CO2배출량")3. 결과변수 CO2배출량과 입력변수간 상관계수 크기를 그래프로 그리기
x=df.select_dtypes(include="number").corr()["CO2배출량"].drop("CO2배출량")plt.bar(x.index, x) plt.ylabel("상관계수")
실습 9 : 회귀 모델링
[예측 모델링]
-
- 단순선형회귀분석
- 다중선형회귀분석
# 데이터 분할 : train, test from sklearn.model_selection import train_test_split # 선형회귀 분석 from sklearn.linear_model import LinearRegression # 모델성능 평가 from sklearn.metrics import r2_score, mean_squared_error# import sklearn error 발생, python version 변경으로 해결1. 단순선형회귀분석
1) 모델링plt.scatter(df["배기량"],df["CO2배출량"]) plt.show()
train, test = train_test_split(df, train_size=0.7) df.shape,train.shape, test.shape((5150, 10), (3604, 10), (1546, 10))lr=LinearRegression() type(lr)sklearn.linear_model._base.LinearRegressionlr.fit(train[["배기량"]],train["CO2배출량"])
vars(lr){'fit_intercept': True, 'copy_X': True, 'n_jobs': None, 'positive': False, 'feature_names_in_': array(['배기량'], dtype=object), 'n_features_in_': 1, 'coef_': array([37.42972939]), 'rank_': 1, 'singular_': array([77.94507477]), 'intercept_': 131.30638860435425}2) 예측
y_pred=lr.predict(test[["배기량"]]) y_predarray([303.48314381, 221.13773915, 206.16584739, ..., 243.59557678, 206.16584739, 262.31044148])lt.scatter(test["배기량"],test["CO2배출량"]) plt.scatter(test["배기량"],y_pred) plt.show()
plt.scatter(test["CO2배출량"], y_pred) plt.xlabel("actual") plt.ylabel("predicted value")
3) 잔차 분석
residual = test["CO2배출량"] - y_pred plt.hist(residual) plt.show()
4) 모델 성능 평가
r2_score(test["CO2배출량"],y_pred)0.72635480413117512. 다중선형회귀분석
1) 모델링
mlr = LinearRegression() mlr.fit(train[["배기량", "CITY연비", "HWY연비"]], train["CO2배출량"])
vars(mlr){'fit_intercept': True, 'copy_X': True, 'n_jobs': None, 'positive': False}2) 예측
y_pred = mlr.predict(test[["배기량","CITY연비", "HWY연비"]]) y_predarray([323.61111865, 258.59505271, 148.88789328, ..., 291.73235229, 220.91062218, 229.41201416])plt.scatter(test["배기량"],test["CO2배출량"]) plt.scatter(test["배기량"],y_pred) plt.xlabel("배기량") plt.ylabel("CO2배출량") plt.show()
plt.scatter(test["CO2배출량"], y_pred) plt.xlabel("actual") plt.ylabel("predicted value")Text(0, 0.5, 'predicted value')
3) 잔차 분석
residual = test["CO2배출량"] - y_pred plt.hist(residual) plt.show()
df # 정형데이터, structured data
4) 모델 성능 평가
r2_score(test["CO2배출량"],y_pred)0.892796282133621 -